Amazon Redshift
в аналитике платежной
системы
в аналитике платежной
системы
В этой статье я хочу рассказать о том, как мы построили аналитическую систему, которая теперь доступна для всех сотрудников и клиентов Xsolla.
Как и у многих интернет-компаний “своя” аналитика у нас была всегда. Много лет мы хранили данные, агрегированные за день, в MySQL и пользовались различными сервисами визуализации (собственный фронтенд с графиками, позже GoodData).
У такого решения есть несколько проблем:
Недовольства и проблемы копились. Стало очевидно, что для того, чтобы мы могли продолжать нормально работать с большими объёмами данных и грамотно их визуализировать, нужно начать поиск новых решений.
Перед командой стояло несколько задач:
Решить эти проблемы удалось за счет использования двух продуктов: Redshift и Slemma.
Позвольте более подробно рассказать о том, как мы работали с данными и Redshift. Мне кажется, на Хабре таких статей не очень много, так что всем интересующимся может быть полезно.
Изначально было принято решение, что данные будем хранить “сырыми”, и будем избегать пред-агрегации любой ценой. Данных у нас не очень много, чтобы считаться Big Data, но уже достаточно, чтобы обычные БД умирали от наших OLAP-запросов. На данный момент примерно 150 млн платежей.
Сначала мы пробовали PostgreSQL. После 10-20 млн записей в таблице с платежами ему становилось плохо. Потом был MonetDB, т.к. мы всем сердцем и кошельком верили в силу open source. Но в итоге словили столько багов и крашей, что даже вспоминать не хочется.
В это же время мы начали делать сервис игровой аналитики совместно со Slemma, где данных в разы больше, чем у нас, и нужно принципиально новое решение. А именно - колоночная распределенная база данных.
Мы изучали HP Vertica и Amazon Redshift. На более “энтерпрайзные” решения даже не смотрели, догадываясь, сколько это будет стоить. В Vertica сразу отпугнула цена и необходимость администрирования кластера своими силами (HP Vertica OnDemand тогда не было). В Redshift очень понравились тонны документации, примеров, отсутствие надобности админить самим и минимальная цена для запуска и тестов ($0.25 в час). В итоге за день был сделан прототип, на базе которого мы и построили всю нашу аналитику.
Создав хранилище данных, нам нужен был инструмент для доступа к хранилищу и визуализации данных, который мог использоваться в компании повсеместно. Мы рассматривали разные варианты:
Ничего из вышеперечисленного нам не подходило, и мы выбрали Slemma, стартап, который полностью покрывал наши требования. В сердце этого решения ROLAP движок Pentaho Mondrian.
Немного о Slemma:
Сразу поясню, как работает Mondrian. Мы пишем xml-конфигурацию с описанием кубов, метрик и измерений, и как они хранятся в базе данных. Пример такого конфига можно посмотреть на гитхабе
Все SQL-запросы Mondrian генерирует сам, в зависимости от MDX запроса, наличия части данных в кэше, ну или просто по своему усмотрению:)
Это значит, что влиять на SQL запросы напрямую мы не можем, только на общую конфигурацию и структуру хранения в БД.
Flat table vs Star schema
В классических базах данных для аналитики широко используется star schema, для ускорения запросов и уменьшения занимаемого места. У вас есть большая таблица фактов (в нашем случае платежи) и небольшие таблицы измерений (платежные системы, игры, страны и т.д.)
В колоночных базах данных ситуация немного другая. Компрессия каждой колонки при хранении нивелирует проблемы с занимаемым местом. А join в некоторых случаях может замедлять запросы.
Кроме этого обновлять данные в одной таблице для нас было проще, чем поддерживать актуальность десятков справочников. В итоге мы выбрали flat table, но всё-таки сделали исключение для справочников, которые не меняются со временем: календарь, страны и т.д
Distribution style
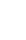
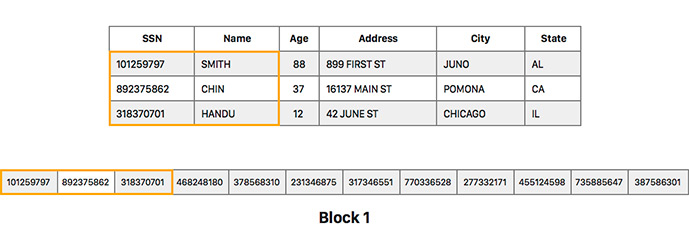
Amazon Redshift - это massive parallel processing database. А значит это вот что: база данных живет не на одном сервере, а на нескольких, и работает как единое целое. На каждом сервере данные хранятся в фрагментах (slices). Их количество равно количеству ядер процессора на сервере. SQL запрос выполняется параллельно на каждом slice. Поэтому очень важно, чтобы данные равномерно были распределены между серверами.
В create table можно выбрать один из distribution style:
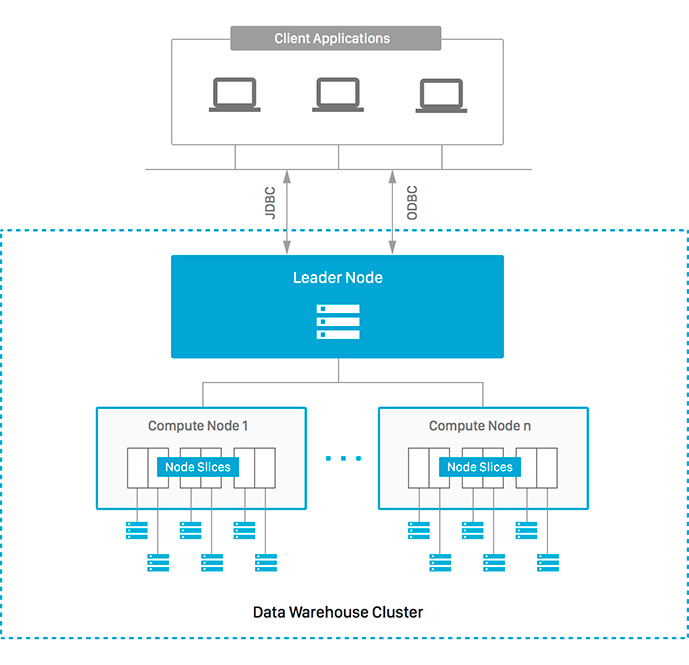
key - данные распределяются между серверами по значению одной из колонок. Redshift гарантирует, что строки с одинаковым значением колонки будут лежать в одном slice.
У колонки должно быть достаточно много уникальных значений, чтобы на каждом сервере хранилось примерно одинаковое количество строк, т.к. это очень важно для скорости выполнения запросов. Если в качестве distkey выбрать ID игры, когда игры бывают очень большие и маленькие, то кластер может “перекосить”.
Второй важный момент это distinct count запросы. Если одинаковые значения колонки будут располагаться на разных нодах, то Redshift’у придется перегнать данные на лидер-ноду, и там выполнить distinct count. Это очень медленно.
В нашем случае user_id был идеальным distkey, т.к. пользователей очень много, а количество уникальных пользователей является одной из самых часто используемых метрик.
all - таблица полностью копируется в каждый slice. Этот diststyle мы используем для маленьких таблиц с измерениями (календарь и география). Таким образом Redshift’у не нужно переносить данные между серверами, чтобы сделать join.
even - данные между серверами распределяются случайно. Мы этот вариант нигде не использовали.
Для каждой таблицы можно выбрать одну или несколько колонок, по значениям которых будут отсортированы все колонки на диске.
Мы выбрали для sortkey дату платежа и вот почему:
данные каждой колонки хранятся в блоках по 1мб. Для каждого блока отдельно хранятся метаданные о его содержимом, например, минимальное и максимальное значение в блоке.
Если мы делаем выборку за последний месяц, Redshift даже не будет читать с диска блоки за другие периоды. Свежие данные запрашиваются в 99% запросов и это позволяет их сильно ускорить.
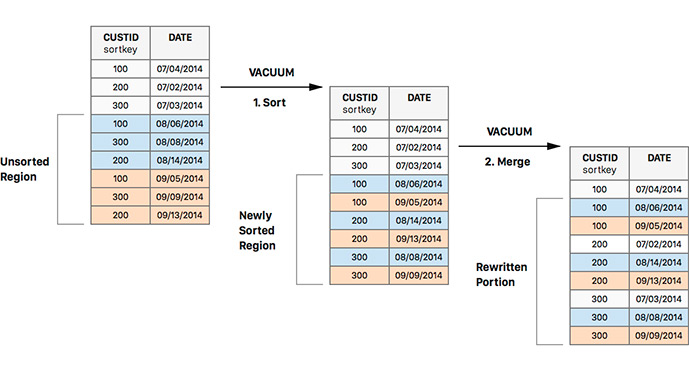
Еще одно преимущество сортировать данные по дате, это ускорение операции vacuum. Vacuum в Redshift сильно отличается от одноименной операции в PostgreSQL. Redshift сам по себе не удаляет “грязные” данные с диска. То есть измененные строки копируются, а старая копия или удаленная строка остаются внутри блоков и просто занимают место.
Также он автоматически не считает метаданные для новых блоков. Все новые данные попадают в так называемые unsorted regions, и запросы в неотсортированные данные и “грязные” блоки будут выполняться медленней.
Vacuum полностью переписывает блоки на диске и приводит их в порядок, поэтому рекомендует делать vacuum таблицы после каждой загрузки данных. Когда новые данные уже отсортированы по дате операция vacuum проходит гораздо быстрее и не сжирает весь I/O на долгое время.
Column compression type
Данные каждой колонки хранятся отдельно и обращение к колонке идет, только если она участвует в запросе. Значит, хранить блоки сжатыми очень эффективно для I/O и занимаемого таблицей места на диске. В redshift много алгоритмов сжатия. От классических lzo и runlength до хитрых text32k со словарём. Подробней о доступных алгоритмах сжатия вы можете почитать в документации.
Также aws предоставляет очень удобный набор для DBA, где есть утилита на python, которая анализирует таблицы и подбирает самые эффективные типы компрессии для каждой колонки. Спустя некоторое время после разрастания нашей flat table мы пересоздали таблицу и сократили её объем с 70 до 50 гб. Эти же данные в gzipped json в S3 у нас занимали сотни гигайбат.
Загрузка данных, ETL
Данные о новых платежах мы загружаем из S3. Этот вариант самый удобный. Данные из MySQL выбираются монструозным селектом с десятками джойнов с помощью select into outfile. Далее построчно перегоняются в json, зипуются, и загружаются в S3.
У json несколько преимуществ:
{ "jsonpaths": [ "$['id']", "$['payment_id']", "$['amount']" ] }
Всё просто и работает очень быстро.
Constraints
Redshift никак не отслеживает целостность ваших данных, там нет внешних ключей или уникальных индексов. Об этом нужно помнить. Например, дубликаты в данных мы удаляем таким запросом:
DELETE from fact_payment where id in ( SELECT id FROM ( SELECT id, row_number() over (partition BY payment_id ORDER BY id DESC) AS rnum FROM fact_payment) t WHERE t.rnum > 1 );
Удобство администрирования
Управлять кластером очень удобно, как и всеми остальными сервисами AWS. Мониторинг производительности, алерты, ресайз, логи и т.д. доступны из веб-интерфейса. Также есть множество системных таблиц, с помощью которых можно понять, что же там внутри происходит.
Полная SQL-совместимость
Часть кода Redshift взята из PostgreSQL, поэтому все 8.х драйверы совместимы и мы легко подключаемся к базе данных из psql, php, java, а также напрямую из ide.
Наличие оконных функций очень помогает. Нам их сильно не хватало в MySQL. С их помощью мы очень быстро удаляем дубликаты, считаем retention и разные другие штуки.
Добавление новых метрик и измерений
Добавлять новые колонки приходится почти еженедельно. Сейчас их уже больше 180. Новая колонка в таблицу добавляется за секунду вне зависимости от размера. В MySQL же для добавления колонки нам приходится почти сутки плясать с pt-online-schema-change.
Для заполнения исторических данных у нас есть простой скрипт. В итоге старые агрегаты забыты как страшный сон.
Slemma идеально подходила для нас, из-за ряда преимуществ:
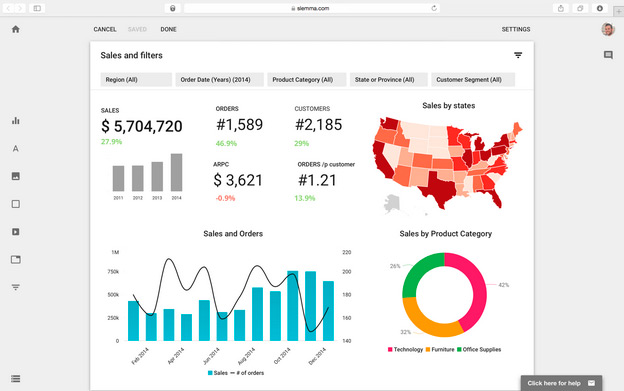
В нашем случае не было необходимости создавать собственное решение. Мы получили идеальное решение, которое прекрасно подходит для визуализации наших данных, а также обладает богатыми возможностями по настройке командной работы. Благодаря этому мы получили возможность не только использовать Slemma в рамках нашей компании, но и предлагать готовое аналитическое решение нашим клиентам.
С переходом на связку Slemma + Redshift у нас расправились крылья в работе с аналитикой. Мы уже загружаем туда данные гугл аналитики, нашу анти-фрод статистику, финансовые проводки и можем быть уверены, что все заработает “из коробки”.
Redshift отлично сработался с Slemma, что позволило нашей компании открыть наши аналитические инструменты всем нашим клиентам:
Пощупать демо аналитики Xsolla можно по ссылке
Спасибо за внимание!